函数式编程中有很多优秀的设计理念值得我们去学习,本文对函数式编程中的基础理念进行了简要的介绍,但更重要的是思考、总结如何将它们应用到我们日常开发中,帮助我们去提升代码的可读性、可维护性等。
©原创文章,转载请注明出处!
Overview
对函数式编程一直有所耳闻,但并未深入研究过,在日常开发中也很少去思考这方面的问题。
直到最近,在开发 flutter 应用时,由于 dart 对函数式编程有较好地支持,对函数式编程有了更新的认识。
纯函数式的编程对我们正常的业务开发来说是一种『乌托邦』式的存在,但其中有很多的设计理念值得我们去学习。
函数式编程相关的文章也有不少,本文的不同之处在于其立足点是:
如何利用函数式编程理念帮助我们写出更好的代码,这也是本文标题叫做函数式思维而不是函数式编程的原因。
函数式编程的理论基础是
λ演算(lambda calculus),但本文并不打算在理论层面上做过多的讨论。
首先,总结一下我个人的观点:函数式编程能给我们带来什么?
简单、清晰、易维护、可复用的代码。
简单、清晰、易维护、可复用可以说是各种架构设计、设计规范追求的第一目标。
那函数式编程又是通过什么方式实现这样的收益的:
- 状态不可变、纯函数;
- 避免引入状态,Pointfree;
- 强调组合、提高复用性;
- 更高层次的抽象,丰富的集合操作。
本文将主要围绕以上几方面对函数式编程展开讨论。
Functional vs. Imperative
函数式编程作为编程范式(Programming Paradigm)之一,与之对应的,也是我们最熟悉的命令式编程(Imperative programming,面向对象编程也属于该范式)。
从思维模式上说:
- 命令式编程:『过程导向』,强调怎么做——关注点在执行步骤,如何一步一步地去完成任务;
- 函数式编程:『结果导向』,强调做什么——关注点在执行结果,相比属于更高层次的抽象,并不关心实现细节。
从理论依据上说:
- 命令式编程:面向计算机的模型,变量、赋值、控制语句等分别对应计算机的物理存储、读写指令、跳转指令;
- 函数式编程:面向数学的模型,将任务以表达式求值的形式表现。
从实现手法上说:
函数式编程是对命令式编程进一步的抽象,屏蔽具体细节,以更加抽象、更加接近自然语言的方式去描述程序的意图,将实现细节交由语言运行时或三方扩展去完成。
从而,开发人员可以从实现细节中解脱出来,站在更高的抽象层次上去思考业务问题。
现状
纯函数、高阶函数、函数一等公民身份、集合操作三板斧等理念极大地提高了语言的创造力、表现力。
虽然无法做到纯函数式,但越来越多的高级语言开始向函数式方向发展,将函数式中的若干重要理念引入自身语法中,如:JavaScript、Swift、Java、dart 等。
纯函数
函数式编程中的『函数』并非我们日常开发中所说的函数(方法),而是数学意义上的函数——映射。
我们知道数学上函数(映射)对相同的输入必定有相同的输出(映射关系是一一对应的)。
因此,函数式编程中纯函数也要满足同样的特征:
- 相同的输入,必定得到相同的输出;
- 函数调用没有任何副作用。
相同的输入,相同的输出
要满足这一点,意味着函数不能依赖除入参以外的任何外部状态。
面向对象中类的成员函数隐式地包含this指针,通过它可以很方便地在成员函数中引用成员变量,这就是纯函数的典型反面教材。
为什么?
实现了函数级的解耦,除了入参没有复杂的依赖关系,这样的函数可读性、可维护性就变得很高。
相信大家在平常开发中,也能有这样的感受:
在理解、维护一个函数时,若其依赖了大量的外部状态,必定会造成不小的认知压力。
除了要理解函数本身的逻辑外,还要去关心其引用的外部状态信息。
有时不得不跳出函数本身去查看这些依赖的外部信息,阅读流程也因此被打断。
无副作用
副作用是指除期望的函数输出值外的任何产出。
常见的副作用包括,但不限于:
- 改变外部数据(如类的成员变量、全局变量);
- 发送网络请求;
- 读写文件;
- 执行DB操作;
- 获取用户交互信息(用户输入);
- 读取系统状态信息;
- 打日志;
- …
总之,纯函数就是不能与外部有任何的耦合关系,包括对外界的依赖以及对外界的影响。
很明显,纯函数的收益主要有:
- 可维护性更高;
- 可测性更强;
- 可复用性更好;
- 高并发更容易,没有多线程问题;
- 可缓存,由于相同的输入,必定有相同的输出,因此对于高频、昂贵的操作可以缓存结果,避免重复计算。
在实际开发中,虽然无法做到所有函数都是纯函数,但纯函数意识应该要深植我们脑海中,尽可能地写更多的纯函数。
高阶函数(Higher-order function)
函数式编程还有一个重要理念:函数是值,即一等函数(first-class),或者说函数有一等公民身份。
这意味着任何可以使用值的地方都可以使用函数,如参数、返回值等。
所谓高阶函数就是其参数或返回值至少有一个是函数类型。
高阶函数使得复用粒度降到了函数级别,在面向对象中复用粒度一般在类级别。
闭包(closure)是高阶函数得以实现的底层支撑能力。
从另一个角度讲,高阶函数也实现了更高层级的抽象,因为实现细节可以通过参数的形式传入,即在函数级别上实现了依赖注入机制。因此,多种GoF设计模式可以通过高阶函数的形式来实现,如:Template Method模式、Strategy模式等。
柯里化(Currying)
简单讲,柯里化就是将『多参数函数』转换成『一系列单参数函数』的过程。1
2
3
4
5
6
7
8
9
10
11// JavaScript
//
function add(x, y) {
return x + y;
}
var addCurrying = function(x) {
return function(y) {
return x + y;
}
}
如上,add是进行加法运算的函数,其接收2个参数,如add(1, 2)。
而addCurrying是经过柯里化处理过的,本质上addCurrying是单参数函数,其返回值也是一个单参数函数。add(1, 2),等价于addCurrying(1)(2)。
柯里化有什么作用?
- 在函数式集合操作上,如:
filter、map、reduce、expand等只接收单参数函数,因此如果现有的函数是多参数,可通过柯里化转换成单参数; - 当某个函数需要多次调用,且部分参数相同时,通过柯里化可以减少重复参数样板代码。
如,有多次调用加法运算的需求,且每次都是加10时,用普通add函数实现:1
2
3add(10, 1);
add(10, 2);
add(10, 3);
而通过柯里化的版本:1
2
3
4var addTen = addCurrying(10);
addTen(1);
addTen(2);
addTen(3);
著名的 JavaScript 三方库lodash提供了curry封装函数,使得柯里化更加方便,如上面的addCurrying用lodash#curry函数实现:1
2
3
4var curry = require('lodash').curry;
var addCurrying = curry(function(a, b) {
return a + b;
});
对函数式编程来说,柯里化是一项不可或缺的技能。
对我们而言,即使不写函数式的代码,在解决重复参数等问题上柯里化也提供了一种全新的思路。
集合操作三板斧
函数式编程语言和面向对象语言对待代码重用的方式不一样。面向对象语言喜欢大量地建立有很多操作的各种数据结构,函数式语言也有很多的操作,但对应的数据结构却很少。面向对象语言鼓励我们建立专门针对某个类的方法,我们从类的关系中发现重复出现的模式并加以重用。函数式语言的重用表现在函数的通用性上,它们鼓励在数据结构上使用各种共通的变换,并通过高阶函数来调整操作以满足具体事项的要求。
在面向对象的命令式编程语言里面,重用的单元是类和用作类间通信的消息,通常可以表述成一幅类图(class diagram)。例如这个领域的开拓性著作《设计模式:可复用面向对象软件的基础》就给每一个模式都至少绘制了一幅类图。在OOP的世界里,开发者被鼓励针对具体的问题建立专门的数据结构,并以方法的形式,将专门的操作关联在数据结构上。函数式编程语言选择了另一种重用思路。它们用很少的一组关键数据结构(如list 、set 、map)来搭配专为这些数据结构深度优化过的操作。我们在这些关键数据结构和操作组成的一套运转机构上面,按需要“插入”另外的数据结构和高阶函数来调整机器,以适应具体的问题。例如我们已经在几种语言中操练过的filter函数,传给它的代码块就是这么一个“插入”的部件,筛选的条件由传入的高阶函数确定,而运转机构则负责高效率地实施筛选,并返回筛选后的列表。
——摘录来自: [美] 福特(Neal Ford). “函数式编程思维 (图灵程序设计丛书)。”
正如上述摘录所说,函数式编程的又一重要理念:在有限的集合(Collection)上提供丰富的操作。
现在,很多高级语言都提供了大量对集合操作的支持,如Swift、Java 8、JavaScript、dart等。
通过这些高度抽象的操作,可以写出非常简洁、易读的代码。
下面对一些常见集合操作作一个简要介绍。
过滤(filter)
过滤就是将列表中不满足指定条件的元素过滤掉,满足条件的元素以新列表的形式返回。
在不同的语言中,该操作的名称有所不同:JavaScript、Swift、Java 8中是filter,dart是where。1
2
3// JavaScript
//
filter(callback(element[, index[, array]])[, thisArg]);
1 | // dart |
1 | // Swift |
1 | // Java |
可以看到,各语言表现形式上虽有所不同,但本质是一样的,即为filter注入一个回调,用于判断其中的元素是否满足指定条件。
如下例,将年龄未满18的过滤掉:1
2
3
4
5// JavaScript
//
const ages = [19, 2, 8, 30, 11, 18];
const result = ages.filter(age => age >= 18);
console.log(result); // 19, 30, 18
通过循环语句实现就不在这列了,两者的对比应该是很明显的。
映射(map)
map就是将集合中的每个元素进行一次转换,得到一个新的值,其类型可以相同也可以不同。1
2
3// JavaScript
//
map(function callback(currentValue[, index[, array]]);
1 | // dart |
1 | // Swift |
1 | // Java |
map是日常开发中使用频率最高的操作之一,如将json转换成dart对象实例:1
jsons.map((json) => BusinessModel.fromJson(json)).toList();
折叠/化约(reduce、fold)
折叠简单讲就是将指定操作依次作用于集合每个元素上,操作结果按操作规则依次叠加,并最终返回该叠加结果(结果类型一般是一个具体的值,而不是Iterable,因此经常出现在链式调用的末端。)。
1 | // JavaScript |
1 | // dart |
1 | // Swift |
1 | // Java |
其中,dart提供了两个操作方法reduce、fold,主要区别在于后者可以提供折叠时的初始值。
1 | List<int> nums = [1, 3, 5, 7, 9,]; |
如上例,reduce是直接对列表元素求和(结果是25),而fold在求和时提供了初始值10(结果是35).
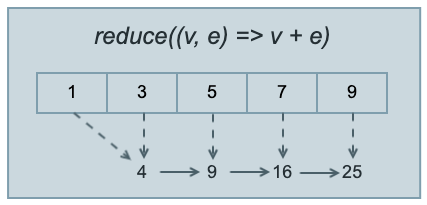
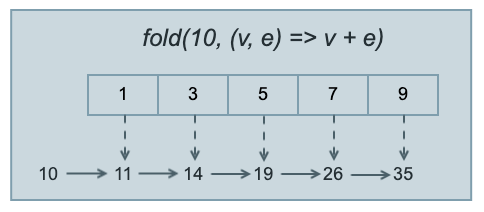
以上reduce、fold都是从左往右进行折叠,有的语言还提供了从右往左折叠的版本,如JavaScript:1
reduceRight(callback(accumulator, currentValue[, index[, array]])[, initialValue])
集合操作还有很多,在此不一一列举。当开始使用这些操作后,会惊奇地发现根本停不下来!
集合上的操作还有一个重要特性:不可变性(immutable),即这些操作不会改变它们正在作用的集合,而是生成新集合来提供操作结果。
有很多的模式或框架都有类似的思想,如:flux、redux、bloc等,它们都强调(强制)任何操作都不能直接修改现有数据,而是在现有数据的基础上生成新数据,最终整体替换掉老数据。
在实际开发中我们也遇到过类似的问题,网络请求在子线程返回数据后直接修改了数据源,导致出现数据不同步的多线程问题。最好的解决方案是网络请求返回后在子线程组装好完整的数据,再到主线程进行一次性替换。
不可变性很好地避免了中间状态、状态不同步等问题,也较好地规避了多线程问题。
同时,不变性语义使得代码可读性、维护推理性变得更好。
因为,通过filter、map、reduce等操作,而不是for、while循环语句操作集合,可以清楚地表达将会生成一个新集合,而不是修改现有集合的意图,代码更加简洁明了。
另外,由于集合上的这些操作的返回值类型大都是集合,因此,当有多个操作作用于集合时,就可以以链式调用的方式实现。这也进一步简化了代码。
看一个 flutter 的例子:1
2
3
4
5
6
7// imperative flutter
//
memberIconURLs
.where(_isValidURL)
.take(4)
.map(_memberWidgetBuilder)
.fold(stack, _addMemberWidget2Stack);
1 | // functional flutter |
上面两个代码片段分别用函数式集合操作、普通for循环语句实现相同的功能:将从后台获取的用户头像url转换成头像widget显示在界面上(最多显示4个,同时过滤掉无效url)。

再看个例子,进一步感受一下两者的差异:1
2
3
4
5
6
7
8
9
10
11
12// imperative JavaScript
//
var excellentStudentEmails_I = function(students) {
var emails = [];
students.forEach(function(item, index, array) {
if (item.score >= 90) {
emails.push(item.email);
}
});
return emails;
}
1 | // functional JavaScript |
上面这两段代码都是获取成绩>=90分学生的 email。
很明显,函数式实现的代码简洁、易读、逻辑清晰、不易出错for循环版本需要很小心地维护实现上的细节问题,还引入了不必要的中间状态:count、url、memberWidget、emails等,这些都是滋生 bug 的温床!
好了,说到减少中间状态就不得不提 Pointfree。
Pointfree
仔细分析上节获取成绩>=90分学生 email 的函数式版本,发现整个过程其实可以分为2个独立的步骤:
- 过滤出成绩>=90分的学生;
- 取学生的 email。
将这两个步骤独立成2个小函数:1
2
3
4
5
6
7
8
9function excellentStudents(students) {
return students
.filter(_ => _.score >= 90);
}
function emails(students) {
students
.map(_ => _.email);
}
这时excellentStudentEmails就可以写成下面这样了:1
2var excellentStudentEmails_N =
students => emails(excellentStudents(students));
这种嵌套调用的写法好像看不出有什么优势。
但有一点可以明确:一个函数的输出(excellentStudents)直接成为另一个函数的输入(emails)。
1 | var compose = (f, g) => x => f(g(x)); |
我们引入另外一个函数:compose,其入参为两个单参数函数(f、g),输出还是一个单参数函数(x => f(g(x)))。
通过compose来改写excellentStudentEmails:1
var excellentStudentEmails_C = compose(emails, excellentStudents);
相比嵌套调用版本excellentStudentEmails_N,组合版本excellentStudentEmails_C具有以下两点优势:
- 可读性更好,从右往左而不是由内而外的阅读顺序更符合我们的思维习惯;
excellentStudentEmails_C版本自始至终从未提及要操作的数据,减少了中间状态信息(状态越多越容易出错)。
没有中间状态,没有参数,数据直接在组合的函数间流动,这也是 Pointfree 最直接的定义。
从本质上说,Pointfree 就是通过一系列『通用函数的组合』来完成更复杂的任务,其设计理念:
- 鼓励写高内聚、可复用的『小』函数;
- 强调『组合』,而非『耦合』,复杂任务通过小任务组合完成,而不是将所有操作耦合在一个『大』函数里。
组合后的函数就像是用管道连接的一样,数据在其中自由流动,无须外界干预:

在 UNIX shell 命令中有专门的管道命令 ‘|’,如:ls | grep Podfile,组合了 ls 与 grep 命令,用于判断当前目录下是否有 Podfile 文件。
注意,对于
excellentStudentEmails来说,excellentStudentEmails_F版本是更好的写法,excellentStudentEmails_C只是用于解说 Pointfree 的概念。
小结
我们不奢望,也没办法做到纯函数式的编程,但函数式编程中很多优秀的设计理念都值得我们去学习和借鉴:
- 状态不可变,避免过多的中间状态;
- 纯函数;
- 高内聚的小函数;
- 多用组合;
- 做好抽象,屏蔽细节;
- …
参考资料
JS 函数式编程指南
函数式编程思维
什么是函数式编程思维
Collection Pipeline
Functional-Light JavaScript